
Multi-agent consensus architecture cuts AI hallucinations by 35.9% in peer-reviewed testing. Proven template for SMB operators building automated workflows where confident errors carry real operational cost.
What does the Robin multi-agent research actually show?
FutureHouse’s Robin system completed a full scientific discovery cycle, from literature synthesis to validated therapeutic candidate, with a small team and AI handling every cognitive task. Published May 2025 on arXiv (2505.13400) and peer-reviewed, Robin is not a concept paper. It produced ripasudil as a novel drug candidate for dry age-related macular degeneration, a connection no researcher had previously proposed. Every cognitive step, strategy, research, hypothesis generation, experiment design, and data interpretation, was owned by the AI while humans ran only the physical lab equipment.
What proof backs this signal?
Robin operates through four specialized agents with locked roles: Crow for rapid literature reconnaissance, Falcon for deep candidate evaluation, Finch for parallel data analysis, and the Robin orchestrator for strategy and routing. Finch runs 10 independent analysis trajectories per dataset simultaneously and only advances a finding if it appears in more than 50% of those runs. Independent research running the same consensus architecture (arXiv:2604.02923) delivered a 35.9% hallucination reduction on the HaluEval benchmark and a 7.8-point gain on TruthfulQA. Peer review, the mechanism that makes scientific findings trustworthy, is now an architectural feature, not a human checkpoint.
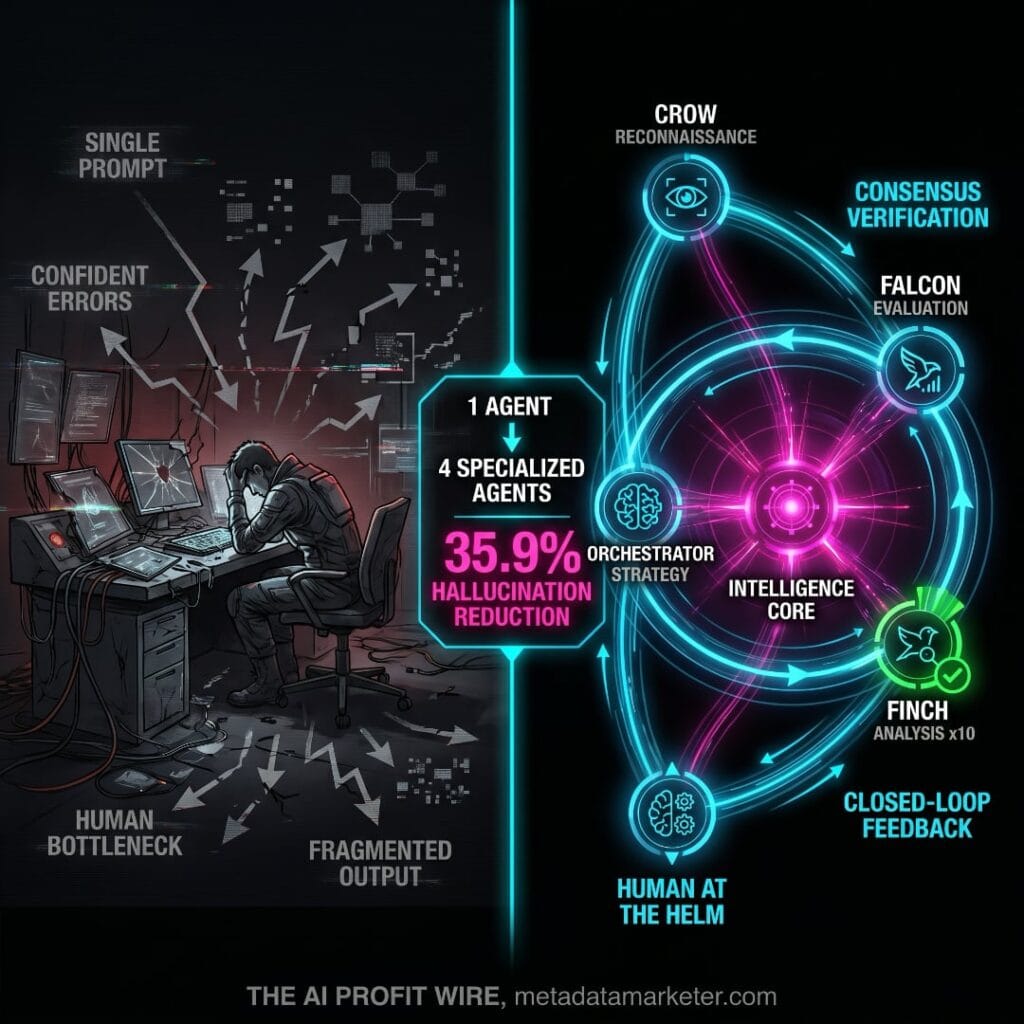
consensus verification versus a single prompt with no quality gate.
Should small business owners care about multi-agent AI systems?
The Robin architecture proves a pattern that applies directly to any knowledge-intensive business workflow. One AI answering questions is a research assistant. Four specialized agents verifying each other before output reaches you is a department. The 35.9% hallucination reduction matters most to operators who cannot afford confident errors in market research, financial modeling, or client-facing content. Track more signals on agentic AI and automation at The AI Profit Wire signals page. The operators who build consensus into their AI workflows now will hold a structural reliability advantage over those still relying on single-model outputs.
Exact Operator Execution Steps
- Identify your most error-sensitive recurring workflow, the one where a confident wrong answer costs real time or money.
- Break the workflow into four locked roles: one agent plans and routes tasks, one researches and drafts, one critiques every output, one validates before anything advances to your review.
- Configure your orchestrator to require agreement from at least two independent agent runs before output clears to your queue.
- Feed real results back into the system after each cycle so the next run improves on the previous one automatically.
- Start with a contained workflow such as market research or content auditing before scaling to financial or client-facing outputs.
Confident AI errors break lean operations when they surface after a post goes out, a report hits a client inbox, or campaign spend is committed. Operating automated systems across multiple business contexts proves the challenge is never capability, it is whether the system checks itself before output reaches the operator. Robin addresses this with peer-reviewed data showing a 35.9% hallucination reduction. That margin represents the gap between autonomous delegation and constant babysitting. For operators running concurrent automated workflows, this distinction determines whether automation buys time or shifts stress to a different part of the process.
Should you act on this signal now?
The Robin paper is not a roadmap for building a drug discovery AI. It is peer-reviewed proof that the multi-agent consensus pattern works at high stakes, and the architecture is available to any operator willing to build it. The cognitive workflows that currently require a skilled analyst can be restructured into agent systems that verify their own outputs before they reach you. Waiting for a plug-and-play product to package this means competitors who build it themselves accumulate a reliability and speed advantage that compounds every week they run it and you do not.
Source: FutureHouse / arXiv:2505.13400