The SMB AI Agent Stack: The 2026 Framework Small Business Owners Actually Need Intelligence Report

In This Report
Running four businesses simultaneously means reading invoices before reading press releases. The AI Profit Wire pipeline monitors 1,000+ signals daily across 100+ sources, and the pattern that surfaces consistently across 2026 SMB intelligence data is one the vendor community does not frame honestly: 76 percent of small business owners now use AI tools, but only 14 percent are running production AI agents. RAND Corporation research confirms that 80 percent of AI projects across organizations of all sizes fail before reaching production, and Gartner documents 50 percent of generative AI projects abandoned after the proof-of-concept phase. The gap exists because most small business owners made the jump from AI tool to AI workflow without a map that showed all four layers of the architecture at once.
The SMB Agent Taxonomy is that map. Four columns. Verified costs. No vendor noise. This framework covers the exact data the AI Profit Wire intelligence pipeline has been tracking across the agent landscape throughout 2026.
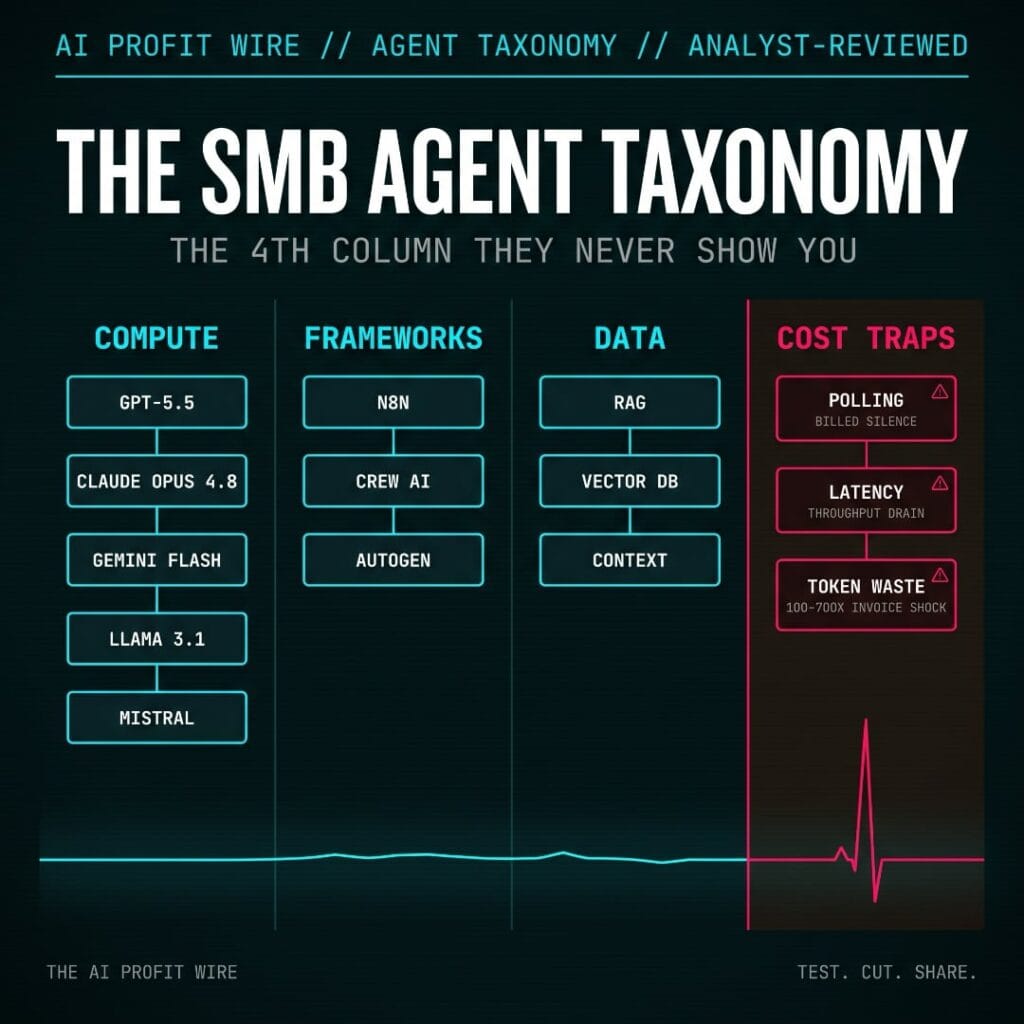
What is the SMB AI Agent Taxonomy and why does it matter for small businesses in 2026?
The SMB Agent Taxonomy maps four architectural layers every production AI agent requires: COMPUTE (the model that processes information), FRAMEWORKS (the logic that orchestrates the workflow), DATA (the memory that gives the agent domain-specific knowledge), and COST TRAPS (the billing patterns that eliminate margin before the project reaches its first renewal). Understanding all four columns simultaneously is what separates the 14 percent running production agents from the 76 percent still running one-off tool experiments. Each column compounds the others: the model selected in COMPUTE determines the per-task cost floor, the framework determines whether that cost scales linearly or quadratically, the data layer determines the accuracy of agent decisions, and the cost traps either addressed or ignored determine whether any of the first three columns deliver any return at all.
Competitive content analysis across five target search queries shows COST TRAPS coverage averaging 0.47 out of 10 across currently published articles, and COMPUTE coverage averaging 0.87 out of 10. No existing published article unifies all four pillars into a single SMB-specific framework with verified cost benchmarks. This framework is the only current reference that maps all four architectural layers simultaneously with sourced cost data specific to small business workloads.
Which AI models should small business owners actually use in 2026?
The COMPUTE column covers five models spanning the full cost spectrum an SMB agent stack requires, from $5.00 per million input tokens at the premium reasoning tier to $0.40 per million tokens for high-volume repetitive workloads. GPT-5.5 (OpenAI) and Claude Opus 4.8 (Anthropic) lead the premium tier, each at $5.00 per million input tokens. GPT-5.5 outputs at $30.00 per million tokens across a 1M-token context window. Claude Opus 4.8, released May 28, 2026, outputs at $25.00 per million tokens with equivalent context, optimized for extended reasoning and safety-critical task handling. Both models deliver the reasoning quality required for high-stakes applications: legal document review, financial analysis, and complex multi-step decision processes where a wrong answer carries a measurable cost.
Gemini 3.5 Flash (Google) occupies the middle tier at $1.50 per million input tokens and $9.00 per million output tokens with a 1M-token context window. It delivers near-Pro reasoning capability and remains accessible on a free tier through Google AI Studio, making it the highest-value entry point for real-time or customer-facing tasks that do not require premium reasoning depth. Llama 3.1 70B (Meta) runs at $0.40 to $0.88 per million tokens on platforms including DeepInfra, Together AI, and Groq, with a 128K-token context window and self-hosted deployment available at zero token cost. Mistral Large 3 (Mistral AI) carries Apache 2.0 licensing with a 256K context window at $0.50 per million input tokens and $1.50 per million output tokens, making it the most underestimated model in the SMB stack: near-frontier reasoning performance at roughly one-tenth the cost of GPT-5.5.
The cost difference between tiers is not marginal. A customer support workflow handling 50,000 monthly interactions costs approximately $6,900 per year on GPT-5.5 and $192 per year on Llama 3.1 70B, calculated at 500 input tokens and 200 output tokens per interaction against published API pricing. The dual-model strategy is the single most impactful cost decision in the entire taxonomy: routing high-stakes tasks exclusively to GPT-5.5 or Claude Opus 4.8 and high-volume repetitive tasks to Llama 3.1 or Mistral Large 3 reduces annual compute costs by 85 to 95 percent compared to running premium models across all workloads.
Which agent frameworks actually work at small business scale?
n8n (v2.23.1) is the strongest option for non-technical small business owners and technically ambitious small teams. The self-hosted Community Edition is free with unlimited executions, running on managed server infrastructure at $3 to $7 per month through services such as PikaPods. The Cloud Starter plan runs $24 per month for 2,500 monthly executions. The break-even case against raw API calls is documented: n8n adds $24 to $60 per month in platform fees compared to raw API call workflows that carry zero platform cost but require $200 to $400 in initial build cost and $100 to $200 per month in ongoing maintenance for teams without dedicated development resources. Break-even occurs within one to two months, and the self-hosted option eliminates the platform fee entirely after that point. With 150,000 GitHub stars and 6,814 community AI workflow templates, n8n has the most documented deployment ecosystem of any framework in this comparison, and the AI Profit Wire tracks agentic framework developments continuously in the daily signals archive.
CrewAI (v1.14.6) is the correct framework for small business teams that require multi-agent orchestration with hierarchical task execution and have technical development resources available. The open-source version carries an MIT license with unlimited agents and executions. The production warning that matters for small teams: multi-agent token multiplication is the dominant cost trap in CrewAI deployments. Chaining five agents multiplies API costs across the entire workflow and compounds the failure surface area, because an Agent A failure can cascade the entire pipeline. The practical starting point is two to three agents maximum with per-agent reliability validated before scaling, and the $99 per month Basic plan’s limit of 100 monthly executions signals clearly who this tier is built for.
AutoGen is in maintenance mode as of early 2026 and should not be the starting point for any new production deployment: Microsoft consolidated AutoGen with Semantic Kernel into the Microsoft Agent Framework (MAF) v1.0, which reached general availability in April 2026, and AutoGen v0.5.7 now receives only security patches and bug fixes, not feature development. Teams with existing AutoGen deployments need a migration plan. New projects should evaluate MAF for Microsoft-ecosystem environments, and n8n or CrewAI for cross-platform flexibility.
How does the right data layer protect your agent’s accuracy without fine-tuning costs?
The DATA column resolves the most expensive misconception in SMB AI deployments: the assumption that fine-tuning is the path to a domain-specific agent. RAG (Retrieval Augmented Generation) is the default choice for small businesses in 2026, and the reason extends beyond cost. OpenAI deprecated self-serve fine-tuning access on May 7, 2026, with full shutdown for existing customers scheduled for January 6, 2027. The most accessible fine-tuning pathway in the market is no longer available to new customers, and the alternatives, Fireworks AI at $0.50 per million tokens and Together AI at $0.48 per million tokens, require ML engineering expertise and specialized dataset preparation that most small teams do not have in-house. The AI Profit Wire’s intelligence methodology covers how these market shifts are evaluated and scored across the pipeline’s daily signal monitoring.
RAG implementation for a small business runs $7,500 to $15,000 for initial setup, with monthly ongoing costs of $350 to $2,850 depending on document volume and query frequency, based on AlphaCorp AI data across 89 deployments. The documented accuracy improvement for domain-specific business queries averages 39.7 percent over base model responses, with 40 to 71 percent hallucination reduction for business-specific content according to Vectara HHEM benchmarks. Small business owners with significant content and SEO operations, for example those running workflows similar to what the NeuronWriter Intelligence Report covers, should note that their proprietary keyword research, content audits, and topic clusters represent exactly the kind of domain knowledge that belongs in a RAG vector store, delivering far more value than a base model working from generic training data. The first-year savings comparing RAG to fine-tuning run $2,000 to $15,000 for a typical small business, and the gap compounds every quarter as the knowledge base evolves, making RAG the structurally superior choice for any team that updates its business information more than once per year.
Qdrant offers the strongest free cloud tier, with permanent access at 1GB RAM and 4GB disk, and managed plans starting at $25 per month, making it the correct starting point for most small businesses in the validation phase. Chroma is the lowest-cost self-hosted option at zero cost under an Apache 2.0 license. Pinecone provides the most accessible managed experience with no self-hosting requirement and a $50 per month minimum. Weaviate restructured to $45 per month minimum in October 2025 with BSD-3 licensing and GraphQL-based hybrid search capability.
What are the three cost traps that eliminate AI agent margins before the first renewal?
The COST TRAPS column is the column vendor taxonomies never include, and it is the column that determines whether the investment in the first three columns produces any return at all. Multiple industry reports converge on 3 to 5 times as the typical first-deployment cost overrun for small businesses that do not address these patterns before launch, with some organizations experiencing 10 times or more. Budget 3 to 5 times your initial API cost estimate as the production baseline, and 10 times as the worst-case planning number.
Polling is the most dangerous trap for new agent deployments because its cost structure is compounding, not linear. Dr. Fadi Shaar documented a case in which a polling loop monitoring open pull requests via the Claude API consumed approximately $6,000 in 26 hours across 46 iterations. The mechanism: LLM APIs rebill the entire conversation history on each call, which means each polling iteration costs more than the last. At scale, 100 concurrent polling agents cost $57 to $118 per hour based on verified cost modeling against Anthropic published rates, and costs grow quadratically as iterations increase. The fix requires no additional infrastructure: webhooks replace polling and invoke agents only when actual work occurs, reducing invocation cost to 5 to 10 percent of polling’s baseline.
Latency traps destroy production deployments in two forms. The first is model selection mismatch: GPT-5.5 Pro in reasoning mode shows a time-to-first-token P50 of 8.4 seconds and P95 of 18.7 seconds. Claude Opus in extended thinking mode shows 28 seconds P50 and 67 seconds P95. Neither profile is viable for any real-time or customer-facing application. The second form is the P95/P50 ratio that applies to every frontier model, which DigitalApplied’s benchmark across 10,000 samples documents at an average of 2.1 times, meaning production latency runs roughly double the marketing figure. This mismatch contributes directly to the 88 percent of AI agents that never reach production deployment according to IDC and Gartner research. Dynamic model routing, directing customer-facing traffic to faster models and batch tasks to cost-efficient models, cuts costs 40 to 60 percent while keeping latency budgets intact.
Token waste is the most pervasive trap and carries the highest-leverage fix. Faraday Machines analysis across 86,000 developers documents 40 to 60 percent of API budgets consumed by operational inefficiencies, including quadratic context accumulation in naive agent loops, redundant system prompts re-sent on every API call, and RAG over-retrieval consuming 40 to 70 percent of token budgets on unnecessary formatting content. A 10-step naive agent loop generates a documented 43.3 times cost overrun against its single-call equivalent based on Augment Code’s verified cost modeling formula. Prompt caching is the highest-ROI fix in the entire cost trap column: it requires zero additional infrastructure, costs nothing to implement beyond a configuration change, and delivers 41 to 80 percent API cost reduction, with Anthropic documenting up to 90 percent savings on cache hits, OpenAI documenting 50 percent cost reduction, and ProjectDiscovery’s published production case study confirming 59 percent savings in a named deployment.
The Margin Obsession
Running four businesses simultaneously means the invoices from one operation always reveal the pattern the others are about to repeat. The current AI billing data reads the same way a restaurant food cost report reads when a new dish was added without running the yield test first: the revenue line looks healthy, the margin line tells a different story, and the gap lives somewhere between the demo and the production deployment. Most small business owners treat the COST TRAPS column as fine print. The 14 percent who are running production AI agents at sustainable margins built for Column 4 first, set the polling boundaries before writing the first webhook, configured prompt caching before optimizing for accuracy, and priced the token waste ceiling before signing any API contract. The four columns of this taxonomy do not have equal weight. Column 4 determines whether the other three are worth building at all.
How should a small business owner sequence their AI agent stack build in 2026?
The taxonomy is not built left to right. The correct sequence for a small business building its first production agent stack reverses the order in which most vendors present the decision. Start with COST TRAPS: document the polling risk, set the monthly API budget ceiling, and configure prompt caching as the baseline configuration before any model is selected. These decisions cost nothing and prevent the 3 to 5 times overruns that converging industry data confirms. Then address DATA: determine what domain-specific knowledge the agent requires, implement RAG using Qdrant’s permanent free tier as the vector store, and populate it with business documents before connecting any model. An agent with accurate retrieval performs better across every model tier.
Then select FRAMEWORKS: n8n self-hosted for most small business teams, CrewAI for those with technical resources and multi-agent requirements, and MAF for Microsoft-ecosystem organizations. Do not start new projects on AutoGen. Then select COMPUTE models using the dual-model strategy from the beginning: Gemini 3.5 Flash or Mistral Large 3 for high-volume tasks, GPT-5.5 or Claude Opus 4.8 reserved for the tasks where a wrong answer carries a measurable cost. Small business owners who have already validated full-funnel automation, for example those running all-in-one platforms such as those covered in the Systeme.io Intelligence Report, are well-positioned to layer RAG-powered agents directly on top of their existing workflow and contact data without rebuilding the operational foundation.
The 62-point gap between the 76 percent of small businesses using AI tools and the 14 percent running production agents is not a capability gap: it is a sequencing and cost architecture gap, and every column of this taxonomy closes a specific section of it by making the hidden costs visible before the first invoice rewrites the budget.
Get the weekly intelligence briefing that covers the tools, pricing shifts, and billing warnings that move these numbers: subscribe to The AI Profit Wire.
Test. Cut. Share.
Last Updated: June 1st, 2026 | Content Type: Category Framework Analysis | Analyst: Moe Sbaiti